この記事では、ブラウザから取得したウェブページのソースコード(HTMLファイル)を、Pythonを使用して処理することで特定の情報を抽出し、CSVファイルにエクスポートする方法について解説します。
例えば、webページに表示されるアイテムの一覧をエクセルファイルに整理したいときや、webページに載っているデータの表からグラフを作成したいときなどに、対象が数十件も数百件もある場合、とても手作業では取り掛かる気が起こらないでしょう。もちろん根気強くやればできないこともないでしょうが、単調でつまらない作業であり、うっかりミスも発生しやすいでしょう。こういった場面にこそコンピュータの活用は有益です。
webページのソースコードの取得
今回は厚生労働省の『平成23年人口動態統計月報年計(概数)の概況』というページのデータを読み込んでみます。10年以上前の古いデータですが、この年以降は当該データをPDF形式で配布しているようなので、HTMLファイルをPythonで処理する方法を解説するという目的のために、ここではあくまでも一つの具体例としてあえて用いています。
Pythonからブラウザを立ち上げ、URLを指定してページを読み込み、HTMLファイルを取得するという作業を一連のプログラムで処理させることもできますが、本記事では、あらかじめ作業ディレクトリ内にHTMLファイルがあることを出発点として話を進めることにします。
てっとり早い方法は、普段使用しているブラウザを立ち上げて次のURL
https://www.mhlw.go.jp/toukei/saikin/hw/jinkou/geppo/nengai11/toukei01.html
にアクセスし、ページを作業ディレクトリに保存する方法です。ただし保存するときに『ページのソース』(Safariの場合)『webページ、HTMLのみ』(Mocrosoft Edgeの場合)などと適宜ご利用のブラウザに合わせてフォーマットを選択する必要があります。ここでは保存したHTMLファイルの名前を『example.html』としておきます。Macの場合、Safariブラウザで取得したwebarchiveファイルをhtml形式に変換するには、ターミナルでファイルが置いてるディレクトリに移動し、以下のコマンドを入力します:
~ % textutil -convert html example.webarchive
保存したHTMLファイルを適当なテキストエディタで開けば、以下のようなソースコードが表示されるはずです:

本記事はHTMLについて解説することが目的ではないので詳細は省きますが、HTMLは『タグ』で挟まれた『要素』を、タグの種類によって階層化し、要素間の階層構造を指定するためのプログラムです。ブラウザはこのプログラムを解読し、指示に沿って構造化された要素を画面に表示するためのソフトウェアです。
webページの要素の取得その1
webページからデータを取得しようという場合、HTMLのなかの特定の要素を取り出すことが必要になります。要素は、その要素を含むタグを指定することで取り出すことができます。そのための準備として
from bs4 import BeautifulSoup path = 'example.html' # ここでは保存したHTMLファイルをexampleという名前にしました with open(path, encoding='shift_jis') as f: # ソースを見るとファイルはshift_jisを用いています soup = BeautifulSoup(f, 'html.parser')
として、要素を取り出せる準備をします。あとはタグ名と、その何個目かを指定することによって要素を取り出すことができます。例えば
soup.find_all("table")[1]
によって、webページの主要な構成要素の一つである下半分の2つ目の表
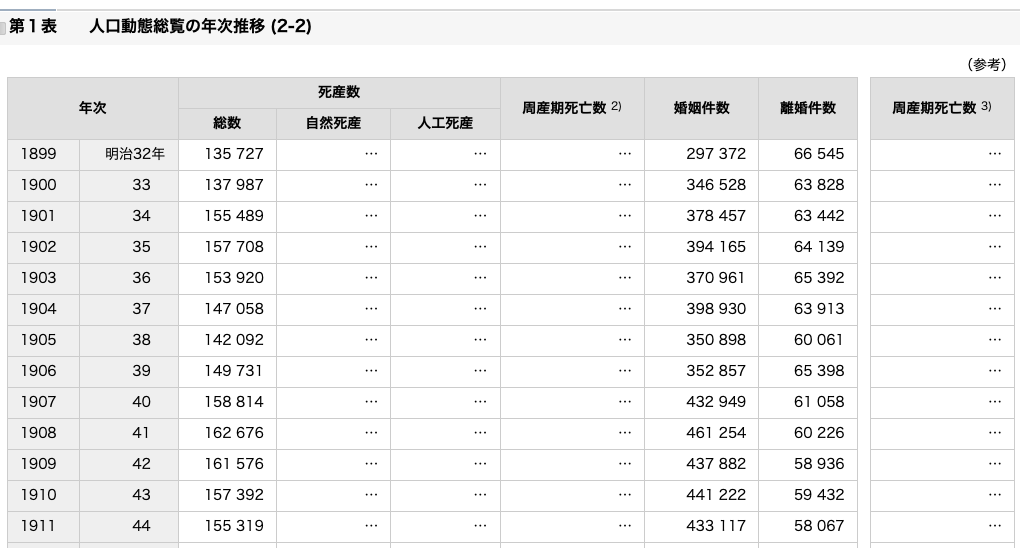
の要素を取り出せます。さらに詳細に絞り込んでいきましょう:
soup.find_all("table")[1].find_all("tr")[0]
とすると
<tr> <th colspan="2" rowspan="2">年次</th> <th colspan="3">死産数</th> <th rowspan="2">周産期死亡数 <span class="sup">2)</span></th> <th rowspan="2">婚姻件数</th> <th rowspan="2">離婚件数</th> <td class="space" rowspan="2"></td> <th rowspan="2">周産期死亡数 <span class="sup">3)</span></th> </tr>
と表示され、下半分の表の項目を取り出すことができました。引数の値を変えてみましょう:
soup.find_all("table")[1].find_all("tr")[2]
とすると
<tr> <th>1899</th> <th class="gengo" nowrap="nowrap">明治32年</th> <td nowrap="nowrap">135 727</td> <td>…</td> <td>…</td> <td>…</td> <td nowrap="nowrap">297 372</td> <td nowrap="nowrap">66 545</td> <td class="space" rowspan="110"></td> <td>…</td> </tr>
より、表の第1列の要素が出力されます。引数の値をさらに変えて
soup.find_all("table")[1].find_all("tr")[3]
としてみると
<tr> <th>1900</th> <th class="year">33</th> <td nowrap="nowrap">137 987</td> <td>…</td> <td>…</td> <td>…</td> <td nowrap="nowrap">346 528</td> <td nowrap="nowrap">63 828</td> <td>…</td> </tr>
より表の第2列の要素が出力されます。よって
soup.find_all("table")[1].find_all("tr")[k+2]
とすることで表の第 (k+1) 列の要素が出力されることがわかります。
webページの要素の取得その2
ここでは下半分の表にある年次(西暦)と、婚姻件数、離婚件数を取り出してみましょう。まず第1列の西暦の要素は以下のようにして抽出されます:
soup.find_all("table")[1].find_all("tr")[2].find_all("th")[0]
から
<th>1899</th>
を得ます。なお、CVSに書き込む際には前後のタグは必要ないので
soup.find_all("table")[1].find_all("tr")[2].find_all("th")[0].text int(_) # あとの処理上、データ型を整数値にしたかったので変更しました
とすることによって、要素の中身だけを出力させることができます。
よって、第 (k+1) 列目の西暦データを取得する関数が以下のようにして作成できます:
def year(k): y = soup.find_all("table")[1].find_all("tr")[k+2].find_all("th")[0].text return(int(y))
確認のためにいくつか出力させてみましょう:
[year(0),year(2),year(8)]
から
[1899, 1901, 1907]
と出力され、上手くいっていることがわかります。続いて婚姻件数も同様に
soup.find_all("table")[1].find_all("tr")[2].find_all("td")[4].text
によって抽出できます。しかしその出力は
'297 372'
といった文字列であり、このままではint関数によって整数型に変換できません。そこで不必要な空白を消去する必要があります。そのためには
'297 372'.replace(' ', '')
とすればよく、結局
def marriage(k): m = soup.find_all("table")[1].find_all("tr")[k+2].find_all("td")[4].text.replace(' ', '') return(int(m))
によって第 (k+1) 列目の婚姻件数データを取得する関数が作成できます。同様にして離婚件数データを取得する関数が作成できます:
def divorce(k): d = soup.find_all("table")[1].find_all("tr")[k+2].find_all("td")[5].text.replace(' ', '') return(int(d))
抽出したデータを格納するリストの作成
[西暦、婚姻件数、離婚件数]を組とするリストを作成してみましょう。上で定義した関数を使えば簡単に作成できます:
List = [] for i in range(110): List.append([year(i), marriage(i), divorce(i)])
リストを表示すれば
[[1899, 297372, 66545], [1900, 346528, 63828], [1901, 378457, 63442], [1902, 394165, 64139], 〜 中略 〜 [2008, 726106, 251136], [2009, 707734, 253353], [2010, 700214, 251378], [2011, 661899, 235734]]
と、求める形になっていることがわかります。
リストをCSVファイルに出力する
webページの処理とは無関係ですが、リストをCSVファイルに出力する方法は以下の通りです:
import csv f = open('example.csv', 'w', newline='') # 出力ファイルの名前をexampleにしました writer = csv.writer(f) writer.writerows( List ) f.close()
これにより次のようなCSVファイルが得られます:

あとはエクセルでCSVを読み込めば、エクセルでデータを取り扱うことができるようになります。
データのプロット
本記事の主題とは無関係ですが、せっかく婚姻件数、離婚件数の時系列データのリストを作成したので、これをプロットしてみましょう:
Ylist = [] for i in range(110): Ylist.append(List[i][0]) Mlist = [] for i in range(110): Mlist.append(List[i][1]) Dlist = [] for i in range(110): Dlist.append(List[i][2]) import matplotlib.pyplot as plt plt.scatter(Ylist, Mlist) plt.scatter(Ylist, Dlist) plt.show()
より次のような図を得ます:
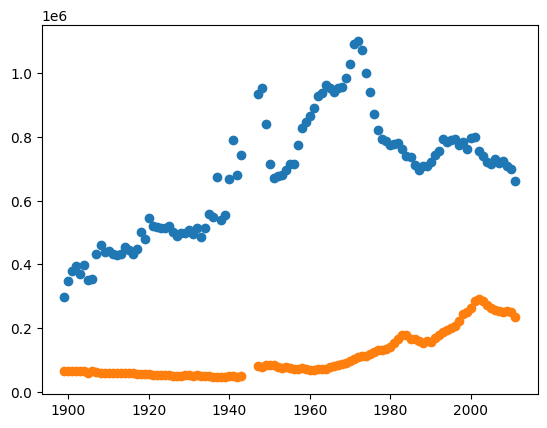
青色が婚姻件数、オレンジ色が離婚件数。縦軸の単位は100万件です。戦後直後、1970年頃の婚姻件数の顕著な増加がわかります。
いかがだったでしょうか。今回扱った単純なデータでも 110 * 3 = 330 件あり、手で入力したのとコンピュータに処理させたのとでは費やす労力に大きな差があることがわかることでしょう。また、web上にあるデータから自分の欲しいデータを取り出し、そしてそこからエクセルに移してさらに詳細に解析したり、グラフを作成して検討したりなど、コンピュータを活用する方法を広げることが、自身の知的活動を広げることにつながることもまた実感できるのではないでしょうか。